Part 1 – The Real Estate Data Quality Problem Part 2
Introduction
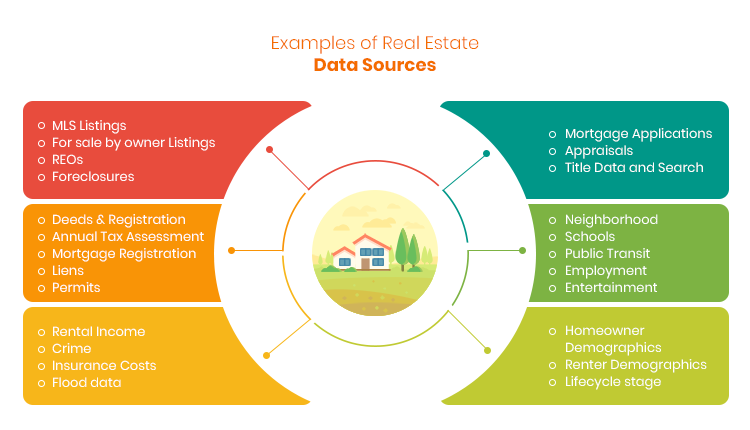
Real Estate data comprises of many categories – characteristics of a property, history of the property and how did it change during its lifetime – renovations, add-ons, permits, etc., current for sale properties, history of sale records, history of tax assessments, current mortgage information, any outstanding liens, utility consumption, neighborhoods, schools, and the list goes on. You can see that there is data about a real property and a lot of additional data about how the property is influenced. And as you read through that partial list of data categories you would have also observed that each of those categories are created and maintained by a different company or a government agency. Given this disparate sources of data and how the real estate industry has evolved, assembling all this in one place to know everything about a single property has become a challenge. Before we begin explaining why this is a challenge, let us briefly explain who uses this data and why this is so important.
Relevance of Data Quality in Real Estate
Housing alone contributes about 15-18% to the GDP of the US economy [1]. If you consider commercial real estate the numbers climb to well over 20% [2]. The real estate ecosystem is comprised of numerous industries and each of them are dependent on data. Here are a few of them in the table below.
| Local Municipalities County Governments Federal Agencies |
Mortgage Lenders (Banks, Credit Unions) Mortgage Brokers Mortgage Servicers Investment Banks |
| Appraisers Home Inspectors Title Companies |
Real Estate Brokers and Agents Home Buyers and Sellers |
| Home Improvement Companies Home Improvement/Repair Contractors |
Builders and Developers Architects Civil Engineers |
| Investment Banks ETF and Fund Managers Retirement and/or Sovereign Funds |
GSAs – Freddie Mac and Fannie Mae |
Here is one reason why data quality matters across these players: Consider the loan processing steps in home buying. The homebuyer applies for a mortgage at a lender and the lender’s underwriter hires an appraiser to determine the actual value of the property before lending a percentage of that value (a maximum of 80% in most cases) to the buyer. Once the mortgage is issued it is often transferred to a mortgage servicer and the mortgage itself is sold to another financial institution to enable securitization of the loan. Securitization enables other investors across the world to participate in the US mortgage market and in turn in the US real estate market. Each party in this chain of activities and especially the investor in the security needs to understand the security’s Value at Risk (VAR) which is directly dependent on the value of the home among many other categories of risk such as borrower risk, market risk, and so on.
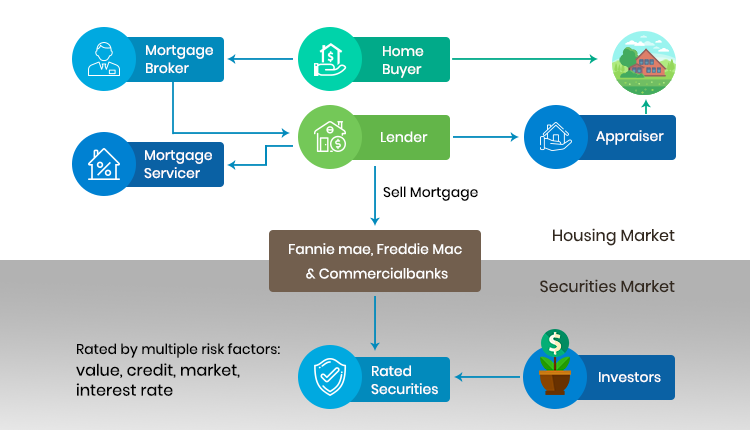
Home valuations are dependent on the property’s characteristics, recent sales in the market, current inventory of homes, neighborhood information, recent development and employment activity in the area, and many more such factors. As you can see accurate and consistent real estate data is highly important to arrive home valuations of high degrees of confidence for every player in the ecosystem.
For instance, consider a property with 4 Bedrooms, 3 Baths, 2,500 sq. ft. living area, on a one acre lot is listed in the MLS as a 5 Bedroom, 3 Bath property since the agent counted an additional room in the basement as a bedroom. By comparing this to other 5 Bedroom, 3 Bath comparable properties, the subject property could get overvalued or other properties can get undervalued if the list price of such a property is used as a comparable. Similarly, the subject property being compared to another one in better condition, or missing out on improvements made to the kitchen or the basement, will reflect an inaccurate value in an appraisal. As a result an appraiser tries not to solely depend on the MLS listing data for their work; she supplements it with onsite inspections to collect detailed information. Appraisals are thereby delayed and it further cuts into the profit margins in the appraisal business. Much worse, this has a direct bearing on the ability of the homeowner or the buyer in closing the transaction. So, unreliable data sources inadvertently exert strong influence on the whole process.
Why is it difficult to maintain data quality in Real Estate?
Of all the sources of information about a particular property, the most dependable data is that made freely available in most counties in the US via the public records act in each state. That covers tax assessment, deeds, mortgages, liens, etc. These data sets are again completely independent typically tied together by an APN (Assessor’s parcel number). But each county or municipality creates and maintains this data in their preferred model even though conceptually they all cover the same types of information. Integrating data from over 3000 counties across the country and unifying them to a single data model is one necessary step to ensure data consistency can be maintained across all properties.
Real Estate listings data gathering, on the other hand, has been a wild west even with the Real Estate Transaction Standard (RETS) maintained by the National Association of Realtors (NAR), which only provides a protocol standard for data exchanges but not a payload standard for the data actually exchanged. Enter Real Estate Standards Organization (RESO) with the RESO standard data dictionary and it has immensely improved consistency in data representation across the various players. But RESO does not address the types of home valuation related data issues discussed earlier (we will presented why RESO is justified with that position in Part 2 of this article). The MLS data capture platforms most often do not enforce any data consistency rules within the system or with the local county/municipality data. Even though a Board of Realtors or MLS may have a recommended format, there could be hundreds, if not thousands of agents, brokers and their assistants that could submit a listing. Much as no two people are alike, their choice of words and descriptions of key features could vary. The description of features is another common area where subjectivity is prevalent. For every person that calls a home a “fixer upper”, another person will say it is “an incredible value, with lots of potential”.
Inaccuracies in the data can be introduced through other means as well. Property characteristics are largely affected by this. Real estate appraisers require the Gross Living Area (GLA) of a home to be the “Above Grade” square footage, which would be how the assessor would report it, but when the property is listed, the Living Area is often, inclusive of finished basements, which can be misleading. Even though the intent is not to create a wrong listing, misinterpretation of the data creates tricky situations during the appraisal process. Data entry errors can create a listing with the wrong number of bedrooms or bathrooms, living area or lot size area. When there are several hundreds of fields to update for a listing and time is limited, these errors tend to multiply exponentially.
Know Your Data – Measure its Quality
As we explained in the previous sections, data quality in real estate is much required but hard to achieve given the integration complexities across the various players. Identifying the individual root causes and fixing them can take a long time, but in the meantime we can try to improve the quality of current data to achieve immediate business objectives.
Before we can “cleanse” the data to improve its quality, we need to be able to identify how bad is the data at hand using a few applicable metrics. It is important to understand that the target quality and the metrics to measure it by depends a lot on the target use for the data. For example, a selling agent is most interested in data related to property characteristics, financing terms, showing instructions, etc. but a home improvement company would be interested in property features, property improvements, etc. Here are a few suggested common metrics to measure the quality of real estate data.
Field Population Statistics with specific focus on the following fields from the RESO standard data dictionary.
| Parcel Number | ListingContractDate | AssociationName |
| Address | StandardStatus | AssociationFee |
| PropertyType | OriginalListPrice | Subdivision |
| PropertySubType | ListPrice | School Districts |
| Lot Size | CloseDate | |
| Zoning | ClosePrice | TotalActualRent |
| NumberOfBuildings | DaysOnMarket | |
| BedroomsTotal | ListAgent Information | |
| BathroomsTotal | ListBroker Information | |
| LivingArea | SellingAgent Information | |
| Tax Year | SellingBroker Information | |
| Tax Value | Public Remarks | |
| Tax Amount | ||
| Land Value | ||
| Improvement Value | ||
| StoriesTotal | ||
| ArchitectureStyle |
Address Standardization measures the extent to which the address components for a property are usable to uniquely locate a property or helps in deriving a high accuracy geocode.
Geocode Accuracy is sometimes required to support accurate property searches for radius or polygon searches. Rooftop accuracy may be required for certain applications but a street side geocode might suffice for many.
Listing Duplication must be reduced as much as possible again depending on the application but at the least listings from the different MLSs will need to be linked with a common unique property id.
Raw listing data from an MLS will trickle in with multiple updates and improving in quality over the first few days or weeks of a property being listed. Listing history records may have to be merged to improve data consistency.
Often a listing will move into a Cancelled/Withdrawn status before it is recorded as Sold. In such cases the listing history data may require a consolidation to drop the superfluous status transitions.
Very often sale and rental listings may get mixed up in different RETS resources/classes. It may be required to reclassify such listings appropriately.
Click here to continue to Part 2 of this article which explores the following ideas.
- Data Quality Best Practices
- Data Standardization vs. Data Quality – What’s the difference
- Practical data quality for real estate
References
- https://www.nahb.org/en/research/housing-economics/housings-economic-impact/housings-contribution-to-gross-domestic-product-gdp.aspx
- http://www.naiop.org/en/Research/Our-Research/Reports/Economic-Impacts-of-Commercial-Real-Estate-2017.aspx
Want access to Data QA Tool?
Please provide your email to be alerted when Data QA Tool is published.