Part 2 – How to improve Real Estate Data Quality?
In Part 1 of this series we broadly covered why data quality is important in real estate, why real estate data quality has become a hard problem to solve, and presented a few examples of how to measure the quality of your real estate data. In this second and final part we will present a few ideas on how you could begin the practice of improving real estate data quality.
Data Quality Best Practices
As you would expect data quality is a common problem in many other industries irrespective of how old or new the industry is. As a result many best practices already exist for managing and improving data quality that can be easily adopted within real estate. Here are a few important areas to focus on.
Data Quality Assessment
Before we can start improving quality we need a solid understanding of the current state of the data. As we presented in the last section of Part 1, knowing how to measure for the quality of your data is a first step. These data quality metrics are very specific to the industry we are in and we have provided a few good starting points.
In addition, to knowing your current state a good data quality assessment practice is required to assess yourself periodically to measure improvements and also measure any data quality leaks due to data trickling into your platform. It is also a great way to present to senior management on the strides you are making in your organization.
Design of the quality metrics needs to be traceable directly to your company’s business objectives which would be different depending on where in the real estate market you play – lead generation, mortgage origination, appraisals, brokerage, etc. Such a traceability is important to get buy-in from the management to invest in data quality.
Data Governance
To have a strong commitment from the organization towards data quality and to continuously support the people, processes, and technologies to maintain the data quality a data governance board must be established with participants from the business and IT. Business participants would be those who are close to the consumption and production of data and the IT participants would be the data architects and modelers. The objectives of the governance board would be to
- Establish data policies and standards
- Defining and measuring data quality metrics
- Discover data related issues and provide resolution paths
- Establish proactive measures to reduce data quality leakage
Data Stewards
One of the most important roles within a data governance board and the overall data management practice is the Data Steward. Data stewards are the ultimate owners of specific sections of the data – usually called subject areas, and they would represent business users and producers of data. The buck stops with the data steward for all data quality issues and the steward takes a leadership role to resolve data accuracy, consistency, or integrity issues.
Data stewards are often the liaisons between the business and the IT department that manages the data for the business. In this role, they are required to work with the business and IT to define relevant quality metrics, have it interpreted and implemented appropriately with the IT department and ultimately showcase their quality improvements that improve business outcomes.
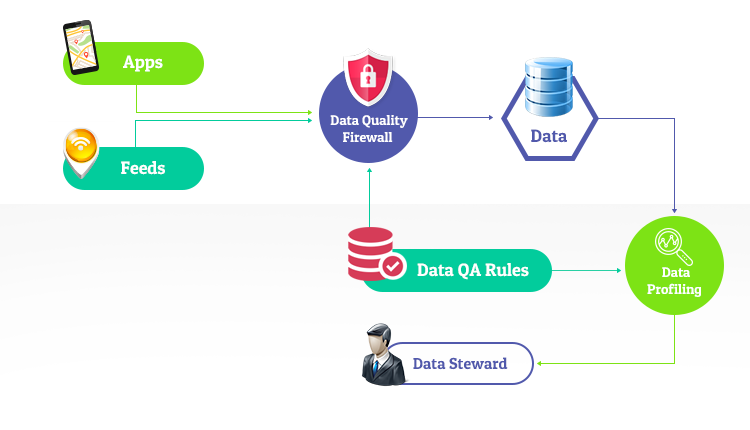
Create a Data Quality “Firewall”
Most data resulting within an organization are traceable broadly to 2 types of sources – applications where users are entering data or data feeds that are processed to load data into data stores.The idea of a data quality firewall is to catch and reject any data that violates data quality rules at the time of its entry into a data store. All data ingestion points will have to hit this one virtual firewall to be validated before being processed and stored.
The keyword above is “virtual” – because it is impractical to create a single system to act as a data quality firewall given the various subject areas of data and the departmental data ingestion points across the organization. The idea is not to create a choke point but a proactive mechanism to catch data quality issues for follow up and resolution before it goes downstream into transactional or analytical systems.
Data Standardization vs. Data Quality – What’s the difference
Does compliance to a data standard mean high data quality? In other words, if your data is Platinum level certified by RESO 1.5 data dictionary would you also considered it to be of high quality? It turns out the answer is not that straightforward.
There are typically 2 different views on data quality – conformance to a standard specification or usability of data for a specific purpose. If we take the first definition the data quality would be very high if a data set is certified by RESO. On the other hand as we discussed in Part 1, an agent could inadvertently enter erroneous listing data or purposefully tweak the listing for improved marketability. This can result in data inconsistency between a public record and a listing record for the same property leaving the user of the data to assign trustworthiness to the data sources before consumption. Since business objectives are driven by data use as opposed to conformance to a standard we prefer the second definition of data quality which is measured by its usability.
Consider another example of standard vs. quality: Assignment of a PropertySubType value of Condominium or Townhouse or Single Family Residence is standards compliant but an erroneous assignment of this field can cause the property to be missed from appearing in IDX searches. In addition, it can also cause valuation issues if not combined and cleansed against other data sources.
Having said that, certain standards specifications include elements of data use as well, in which case conformance to standards and usability begin to mean the same. But given the various uses of a particular data set it is in unfair to expect a standards organization to completely define all the usability of specs for the data resulting in an unwieldy standard that may reduce its adoption.
Here are some typical data quality concerns to consider:
| Completeness | Are we missing any values of critical fields? |
| Validity | Is the data in a field valid? Does the whole record match my rules? |
| Uniqueness | How much of our data is duplicated? |
| Consistency | Is information consistent within a single record, across multiple records, and across multiple data sets? |
| Accuracy | Does the data represent reality? |
| Temporal Consistency & Accuracy | Does a snapshot in time represent reality at that time and are all data sets consistent with that snapshot? |
As you can see, a data standard such as RESO would not be able to answer the above for all the real estate ecosystem players. We could define detailed rules for each of the concerns above and such rules will look different in a mortgage company and a sales lead generation company.
Practical data quality for real estate
Now let us bring all this down to a few specific takeaways to improve the quality of data in your company. We will define these in a few steps to begin with. But certainly stay tuned into our blog for future posts on this topic where we will continue to provide specific rules and heuristics you could implement.
Many of the activities below must be driven by an appointed data steward for each major data set you are dealing with – assessment, listings, deeds, mortgages, permits, etc.
Identify critical fields
The first step in your data quality journey is to identify the most critical fields for your particular application. Out of the 639 fields contained in the RESO 1.6 data dictionary, you would want to identify the fields that are required for your computations. There are some fields commonly required for any application and were listed in Part 1 of the article and repeated here for quick reference:
| Parcel Number | ListingContractDate | AssociationName |
| Address | StandardStatus | AssociationFee |
| PropertyType | OriginalListPrice | Subdivision |
| PropertySubType | ListPrice | School Districts |
| Lot Size | CloseDate | |
| Zoning | ClosePrice | TotalActualRent |
| NumberOfBuildings | DaysOnMarket | |
| BedroomsTotal | ListAgent Information | |
| BathroomsTotal | ListBroker Information | |
| LivingArea | SellingAgent Information | |
| Tax Year | SellingBroker Information | |
| Tax Value | Public Remarks | |
| Tax Amount | ||
| Land Value | ||
| Improvement Value | ||
| StoriesTotal | ||
| ArchitectureStyle |
Define Data Quality Rules
The next step is to define a set of rules that will consider 2 dimensions to begin with:
Data Quality Concerns: Completeness, Validity, Uniqueness, Consistency, Accuracy, and Temporal Consistency & Accuracy.
Extent of measurement: Single record, multiple history records of the same property, multiple history records of the same listing, multiple data sets (public records and listings)
You would end up with rules for each field, for each type of record, for a data set, and rules that cut across multiple data sets. These rules would validate the field, a record, a set of records, or the whole data set. Execution of these rules would result in either errors or warnings about the quality of your data.
Discovery with Data Profiling
Data Profiling helps you run a statistical analysis on the data to discover hitherto unknown problems
For example, we usually expect PropertySubType values to be always one of the known ones. But as new data gets processed, we might discover that certain PropertySubType mappings are absent in our standardization routines and as a result non-standard PropertySubTypes may be getting added to our DB.
To catch such issues, a data profiling capability will provide detailed stats on field populations, null counts, blank counts, and also field value distributions. For the PropertySubType values, the field value distribution will reveal to us that there is a new PropertySubType value with over 100,000 entries. This will mean that we should remap these values as required.
Running a data profiler periodically will help identify issues that creep up into the data. Note that a data quality firewall would only prevent “unclean” data when we have modeled such cleansing rules or quality rules within that firewall. But for previously unknown issues that get loaded via daily incremental data ingestions, we need to discover the issues and model prevention rules into the firewalls.
Establish Data Quality Metrics
Having defined the rules it is time to measure your quality against the rules you have established. Common quality metrics are:
- Number of records that failed a particular quality rule
- Field population thresholds and where we fall short
- Field value distributions
- Number of records with invalid data for each field
- Number of records that failed a record level quality rule
- Number of multi-record quality rule failures
- Number of data-set level quality rule failures
For each of the above it is important to understand the trends and so you need to run the Data Profiler in regular intervals – weekly or monthly, to know how your data quality is trending – improving, getting worse, or discover issues that did not exist before.
Enforce the rules at the data ingestion points
This is the first and proactive step in improving and maintaining high quality of data.
Having defined the rules for measuring data quality, it is now important to maintain a higher quality data by ensuring we enforce these rules at the time data is created in the organization. Get the data steward to become the evangelist for the rules he/she has defined to work with each data origination point to implement the validation rules.
Define Heuristics for Quality Improvement
The reactive posture to data quality improvement is considered more of a data cleansing process and is a required element of a data quality practice. Most of the times, you are not in control of the data origination points and if the rule enforcement at the data origination point is too restrictive you might not have enough data for your applications. And hence the need for a reactive measure to cleanup data you have received.
There are broadly 2 alternatives – either perform the cleanup and then put it through a highly restrictive data quality firewall or have a lenient firewall with a downstream cleaning process. The choice depends very much on your application and its ability to deal with imperfect data.
Any data quality improvement mechanism is dependent on a set of heuristics that the data steward and the data architects work together to define. For example, you could reclassify a rental listing correctly by looking at the listing price and comparing it to local median sale price and to the median rental price. A strong partnership between a data steward and the data architect is necessary to define and develop these cleansing heuristics.
It is also recommended that you maintain a list of all active and retired heuristics used for cleansing. Another need alongside data cleansing is the ability to track the data lineage where you would keep track of the source of the cleansed data and the heuristics that caused the data to be modified.
Conclusion
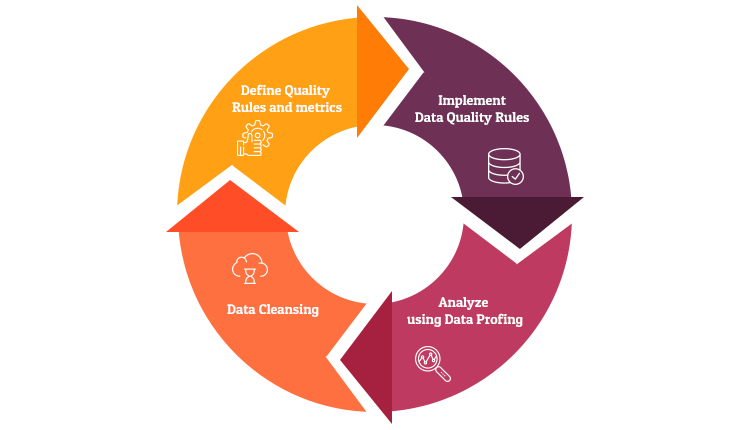
Data quality is a cyclical process that begins with establishing rules, implementing them to measure quality, profiling the data, cleaning up the data as required, and finally go back to tweaking the rules to execute the cycle once more. The target metrics would start small but continue to tighten it with time.
We hope this article provided an overview and some key takeaways to implement a good data quality practice within your real estate technology platform. We will continue this conversation with more blog posts to provide you:
- Practical data quality rules and metrics
- Data cleansing heuristics to implement
- Machine learning techniques in real estate data cleansing
We are planning to release our Data QA Tool specialized for real estate data free to the community. Please sign up here to be notified when the tool is released.
Want access to Data QA Tool?
Please provide your email to be alerted when Data QA Tool is published.