Using OCR, Image Processing, and AI for Appraisal Digitization
- 08/15/2021
- PropMix Communications
- 0
Challenges in extracting data from a PDF Appraisal Form
We define Appraisal Digitization as the process of extracting structured real estate valuation data from various appraisal forms produced by appraisers and submitted to their clients. While these days most appraisals are in fact produced using forms software that generate a parseable PDF the structured data used by the appraiser is seldom passed on to downstream users of the appraisal.
The Mortgage Industry Standards Maintenance Organization (MISMO) XML is a well documented widely accepted standard for the exchange of valuation data between the parties in many mortgage related business processes. However, the MISMO XML gets lost somewhere in the handoffs across the numerous business participants in the mortgage process and only the PDF document of the appraisal is exchanged. In addition, in many cases the PDF gets printed and then rescanned before being passed downstream resulting in what the industry calls a second or later generation PDF – in other words scanned PDFs.
Our goal is to recreate the MISMO XML from the PDF – either a parseable first generation PDF or from a scanned second or later generation PDF. This article discusses some of the major challenges we stumbled upon and the solution approaches we chose.
Before we get started
Here are a few references for the various appraisal form structures and the MISMO XML standard to help you appreciate the challenges discussed in the remainder of this article.
Appraisal Form 1004 UAD: https://singlefamily.fanniemae.com/media/12371/display
Appraisal Form 1073 UAD: https://singlefamily.fanniemae.com/media/14251/display
MISMO XML Standard: https://www.mismo.org/get-started/adopt-the-standards
Form Standards and Customizations
While the UAD standard provides general guidelines for the form, the exact structure of the Appraisal Form does vary for some of the following reasons:
The UAD does not impose a definition of the forms dimensions and exact placement of a field or its value on the form, but it only provides a definition of the relative positioning of the fields. The farthest the UAD goes is to define clearly the lines and the expected fields in each line.
Given this, each forms-software provider might have a slightly different position on the page for the fields and values.Most forms software also provide many customization features for the appraiser or the AMC to change:
The fonts and font size
The page size
The header and footer content on each page of the form
The sequencing of the pages within a form while generally following a standard, additional comparable grid pages can be introduced anywhere in the form.
These variations pose interesting challenges for the data extraction steps.
Determining the first page and remaining pages of the form
Most appraisal forms start with a cover page followed by a few additional pages for invoice or valuation summary, etc. before the UAD form begins. In fact, the UAD form is only 6-pages with may be an additional one or two pages for more comparable sales while the whole appraisal document may be 30-40 pages including supporting information such as photos, license information, flood maps and plat maps.
As a result, it is important for the data extraction step to identify where the actual UAD form begins.
Another similar problem is the identification of the repeating comparable sales or listings page which can appear anywhere in the document either within the main UAD form or anywhere else in the document – for example between two photo pages.
To balance performance against accuracy we use Support Vector Machines (SVM) to classify each page into a known set of page categories.
Optical Character Recognition (OCR) is not perfect
We use OCR only for the second or later generation PDFs that contain scanned images. OCR works very well if the scanned document is of very high quality, but in most cases the OCR will work with errors. For example, the extraction from the first line of the 1004 form may read as follows:
Property Addre55 2916 89th ST City LUBB0CK State TX Zip C0de 79423
Notice the numbers “55” and the “0” in the middle of the City value and field name – “Zip C0de”. We use a dictionary and Levenshtein Distance based field name correction process before beginning to parse the field values and in turn apply another dictionary for the values to improve the data quality.
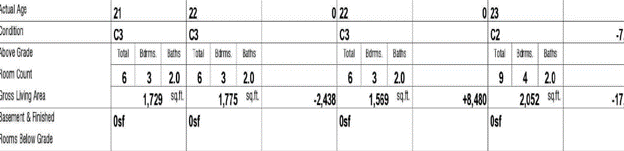
Tables with empty cells and/or misaligned rows
All appraisal forms contain table structures where some of the cells in the tables may be empty and/or the cells may be slightly misaligned in a scanned PDF.
Extracting table structures is a complex problem even for first generation PDFs because we need to identify the empty cells to correctly allocate values to the right cell.
The plain OCR process does not understand the table structures and instead will provide all the text in a sequential format with no separation of rows or columns.
We use image processing techniques to the first understand the columns identify the column start and end locations as shown by the blue lines in the diagram below:

When using the OCR data we then use the x-coordinate position of the bounding box of the to allocate the value to the appropriate column.
We then use a variation of bucket sorting of the y-coordinates of the text bounding boxes to allocate the value to the appropriate rows. Note that the bucket sorting process is also used to allocate the data to the appropriate line of the document.
Sub-Tables within large tables
There are many places in the UAD forms where a table may contain sub-cells or sub-tables. A similar process as above along with a few additional algorithms for determining the mid-points of the cells is used to derive the relative positions.
Checkbox Detection within the form and within table structures
In both first and second or later generation PDFs the extraction of checkbox status and the associated field names is not supported by the PDF parsing or the OCR engine. The OCR engine may result in a value of “X” or “Y” or some other special symbol when it encounters a checkbox.
We employ a combination of image processing and dictionary methods to derive the checkbox status and field names.
Image processing detects the checkbox boundaries and their state – checked / unchecked – along with the position of the checkbox. This information is then fed into the main data extraction process to apply form specific heuristics to determine the field the checkbox represents.
Conclusion
We hope this article provided an appreciation for the complexities of extracting data from appraisal forms. Many of these challenges are not unique to appraisal forms but common to many other documents that have similar structures.
We continue to challenge ourselves to achieve the maximum possible quality for the output generated by the digitization process. We have a motto that drives us: “if a human can read and extract, our digitization process should be able to do better without errors.”